
django-uuslug汉字转拼音出现的小问题,可能是BUG.
By:Roy.LiuLast updated:2019-09-03
在用python/Django开发网站的过程中,很多人为了更友好的SEO, 会采用将汉字转换成拼音的方式放在url里面,这样对搜索引擎比较友好。我今天也尝试了这么一个第三方库 django-uuslug, 不过我一测试就出问题了。好像是老外不懂中文,做出来的一个bug.
一、安装 django-uuslug
二、测试程序
打印出来的结果如下:
发现问题所在了吗,中文 “什么”的汉语拼音却变成了"shi yao", 真不知道这老外是什么骚操作。 但是后面的“甚至” 的汉语拼音又是对的。所以这应该是个bug, 不过对老外来说,能做到这样已经不容易了。
三、怎么解决呢
跟踪代码,你会发现,最终处理的过程在 text_unicode.py的这个方法中:
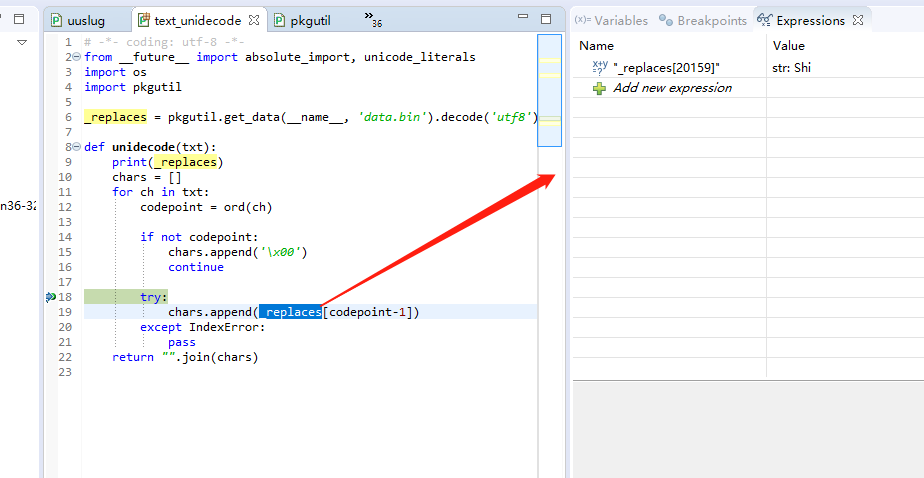
然而这些字库拼音显然在data.bin这个文件里面,在对应的python安装package里面找到这个文件,打开是这样的,没办法编辑呀,不知道是哪一个,为什么不用纯文本呢,非得用bin格式. 我记得以前见过一个是文本格式的,自己可以编辑修改的,但这个不行。但是这个bin格式看起来应该是python将一个对象序列化成文件而形成的,应该可以通过反序列化方式还原成list, 然后找到对应的位置修改后,再序列化成文件保存为data.bin,应该就可以解决这个问题。

如果想简单,就只能在上面的方法里面,自己再增加一个列表或者字典。自己来匹配,来解决这种拼音不正确的问题。
如果想通过序列化,反序列化方式,就需要再上面的代码中找到_replaces中对应的位置,修改后,然后再保存.
具体的代码就不写了,思路应该没问题。
另外在github上提了一个bug, 不知道有没有用https://github.com/un33k/django-uuslug/issues/22
一、安装 django-uuslug
pip install django-uuslug
二、测试程序
#coding:utf-8
from uuslug import slugify
if __name__ == "__main__":
txt = "什么东西-甚至-是么"
slug_word = slugify(txt)
print(txt + "------" + slug_word)
txt = "中文识别老大难问题"
slug_word = slugify(txt)
print(txt + "------" + slug_word)
txt = "kala is a dog"
slug_word = slugify(txt)
print(txt + "------" + slug_word)
打印出来的结果如下:
什么东西-甚至-是么------shi-yao-dong-xi-shen-zhi-shi-yao 中文识别老大难问题------zhong-wen-shi-bie-lao-da-nan-wen-ti kala is a dog------kala-is-a-dog
发现问题所在了吗,中文 “什么”的汉语拼音却变成了"shi yao", 真不知道这老外是什么骚操作。 但是后面的“甚至” 的汉语拼音又是对的。所以这应该是个bug, 不过对老外来说,能做到这样已经不容易了。
三、怎么解决呢
跟踪代码,你会发现,最终处理的过程在 text_unicode.py的这个方法中:
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
import os
import pkgutil
_replaces = pkgutil.get_data(__name__, 'data.bin').decode('utf8').split('\x00')
def unidecode(txt):
chars = []
for ch in txt:
codepoint = ord(ch)
if not codepoint:
chars.append('\x00')
continue
try:
chars.append(_replaces[codepoint-1])
except IndexError:
pass
return "".join(chars)
然而这些字库拼音显然在data.bin这个文件里面,在对应的python安装package里面找到这个文件,打开是这样的,没办法编辑呀,不知道是哪一个,为什么不用纯文本呢,非得用bin格式. 我记得以前见过一个是文本格式的,自己可以编辑修改的,但这个不行。但是这个bin格式看起来应该是python将一个对象序列化成文件而形成的,应该可以通过反序列化方式还原成list, 然后找到对应的位置修改后,再序列化成文件保存为data.bin,应该就可以解决这个问题。
如果想简单,就只能在上面的方法里面,自己再增加一个列表或者字典。自己来匹配,来解决这种拼音不正确的问题。
如果想通过序列化,反序列化方式,就需要再上面的代码中找到_replaces中对应的位置,修改后,然后再保存.
具体的代码就不写了,思路应该没问题。
另外在github上提了一个bug, 不知道有没有用https://github.com/un33k/django-uuslug/issues/22
From:一号门
Previous:记录自己常用在kibana中用的DSL查询语句,以后方便参考
COMMENTS