
Spring Batch Partitioning example
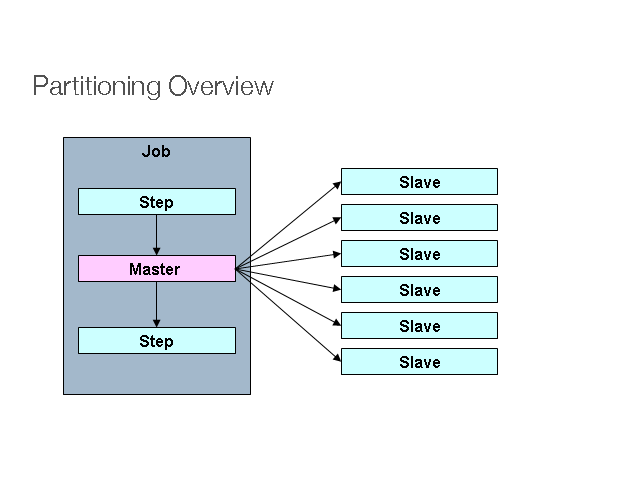
Photo Credit : Spring Source
In Spring Batch, “Partitioning” is “multiple threads to process a range of data each”. For example, assume you have 100 records in a table, which has “primary id” assigned from 1 to 100, and you want to process the entire 100 records.
Normally, the process starts from 1 to 100, a single thread example. The process is estimated to take 10 minutes to finish.
Single Thread - Process from 1 to 100
In “Partitioning”, we can start 10 threads to process 10 records each (based on the range of ‘id’). Now, the process may take only 1 minute to finish.
Thread 1 - Process from 1 to 10 Thread 2 - Process from 11 to 20 Thread 3 - Process from 21 to 30 ...... Thread 9 - Process from 81 to 90 Thread 10 - Process from 91 to 100
To implement “Partitioning” technique, you must understand the structure of the input data to process, so that you can plan the “range of data” properly.
1. Tutorial
In this tutorial, we will show you how to create a “Partitioner” job, which has 10 threads, each thread will read records from the database, based on the provided range of ‘id’.
Tools and libraries used
Maven 3
Eclipse 4.2
JDK 1.6
Spring Core 3.2.2.RELEASE
Spring Batch 2.2.0.RELEASE
MySQL Java Driver 5.1.25
P.S Assume “users” table has 100 records.
users table structure
id, user_login, user_passs, age 1,user_1,pass_1,20 2,user_2,pass_2,40 3,user_3,pass_3,70 4,user_4,pass_4,5 5,user_5,pass_5,52 ...... 99,user_99,pass_99,89 100,user_100,pass_100,76
2. Project Directory Structure
Review the final project structure, a standard Maven project.

3. Partitioner
First, create a Partitioner implementation, puts the “partitioning range” into the ExecutionContext. Later, you will declare the same fromId and tied in the batch-job XML file.
In this case, the partitioning range is look like the following :
Thread 1 = 1 - 10 Thread 2 = 11 - 20 Thread 3 = 21 - 30 ...... Thread 10 = 91 - 100
RangePartitioner.java
package com.mkyong.partition;
import java.util.HashMap;
import java.util.Map;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.item.ExecutionContext;
public class RangePartitioner implements Partitioner {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> result
= new HashMap<String, ExecutionContext>();
int range = 10;
int fromId = 1;
int toId = range;
for (int i = 1; i <= gridSize; i++) {
ExecutionContext value = new ExecutionContext();
System.out.println("\nStarting : Thread" + i);
System.out.println("fromId : " + fromId);
System.out.println("toId : " + toId);
value.putInt("fromId", fromId);
value.putInt("toId", toId);
// give each thread a name, thread 1,2,3
value.putString("name", "Thread" + i);
result.put("partition" + i, value);
fromId = toId + 1;
toId += range;
return result;4. Batch Jobs
Review the batch job XML file, it should be self-explanatory. Few points to highlight :
For partitioner, grid-size = number of threads.
For pagingItemReader bean, a jdbc reader example, the #{stepExecutionContext[fromId, toId]} values will be injected by the ExecutionContext in rangePartitioner.
For itemProcessor bean, the #{stepExecutionContext[name]} values will be injected by the ExecutionContext in rangePartitioner.
For writers, each thread will output the records in a different csv files, with filename format - users.processed[fromId]}-[toId].csv.
job-partitioner.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:util="http://www.springframework.org/schema/util"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.2.xsd
">
<!-- spring batch core settings -->
<import resource="../config/context.xml" />
<!-- database settings -->
<import resource="../config/database.xml" />
<!-- partitioner job -->
<job id="partitionJob" xmlns="http://www.springframework.org/schema/batch">
<!-- master step, 10 threads (grid-size) -->
<step id="masterStep">
<partition step="slave" partitioner="rangePartitioner">
<handler grid-size="10" task-executor="taskExecutor" />
</partition>
</step>
</job>
<!-- each thread will run this job, with different stepExecutionContext values. -->
<step id="slave" xmlns="http://www.springframework.org/schema/batch">
<tasklet>
<chunk reader="pagingItemReader" writer="flatFileItemWriter"
processor="itemProcessor" commit-interval="1" />
</tasklet>
</step>
<bean id="rangePartitioner" class="com.mkyong.partition.RangePartitioner" />
<bean id="taskExecutor" class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
<!-- inject stepExecutionContext -->
<bean id="itemProcessor" class="com.mkyong.processor.UserProcessor" scope="step">
<property name="threadName" value="#{stepExecutionContext[name]}" />
</bean>
<bean id="pagingItemReader"
class="org.springframework.batch.item.database.JdbcPagingItemReader"
scope="step">
<property name="dataSource" ref="dataSource" />
<property name="queryProvider">
<bean
class="org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="selectClause" value="select id, user_login, user_pass, age" />
<property name="fromClause" value="from users" />
<property name="whereClause" value="where id >= :fromId and id <= :toId" />
<property name="sortKey" value="id" />
</bean>
</property>
<!-- Inject via the ExecutionContext in rangePartitioner -->
<property name="parameterValues">
<map>
<entry key="fromId" value="#{stepExecutionContext[fromId]}" />
<entry key="toId" value="#{stepExecutionContext[toId]}" />
</map>
</property>
<property name="pageSize" value="10" />
<property name="rowMapper">
<bean class="com.mkyong.UserRowMapper" />
</property>
</bean>
<!-- csv file writer -->
<bean id="flatFileItemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter"
scope="step" >
<property name="resource"
value="file:csv/outputs/users.processed#{stepExecutionContext[fromId]}-#{stepExecutionContext[toId]}.csv" />
<property name="appendAllowed" value="false" />
<property name="lineAggregator">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="delimiter" value="," />
<property name="fieldExtractor">
<bean
class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor">
<property name="names" value="id, username, password, age" />
</bean>
</property>
</bean>
</property>
</bean>
</beans>The item processor class is used to print out the processing item and current running "thread name" only.
UserProcessor.java - item processor
package com.mkyong.processor;
import org.springframework.batch.item.ItemProcessor;
import com.mkyong.User;
public class UserProcessor implements ItemProcessor<User, User> {
private String threadName;
@Override
public User process(User item) throws Exception {
System.out.println(threadName + " processing : "
+ item.getId() + " : " + item.getUsername());
return item;
public String getThreadName() {
return threadName;
public void setThreadName(String threadName) {
this.threadName = threadName;5. Run It
Loads everything and run it... 10 threads will be started to process the provided range of data.
package com.mkyong;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class PartitionApp {
public static void main(String[] args) {
PartitionApp obj = new PartitionApp ();
obj.runTest();
private void runTest() {
String[] springConfig = { "spring/batch/jobs/job-partitioner.xml" };
ApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
Job job = (Job) context.getBean("partitionJob");
try {
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Exit Status : " + execution.getStatus());
System.out.println("Exit Status : " + execution.getAllFailureExceptions());
} catch (Exception e) {
e.printStackTrace();
System.out.println("Done");Console output
Starting : Thread1 fromId : 1 toId : 10 Starting : Thread2 fromId : 11 toId : 20 Starting : Thread3 fromId : 21 toId : 30 Starting : Thread4 fromId : 31 toId : 40 Starting : Thread5 fromId : 41 toId : 50 Starting : Thread6 fromId : 51 toId : 60 Starting : Thread7 fromId : 61 toId : 70 Starting : Thread8 fromId : 71 toId : 80 Starting : Thread9 fromId : 81 toId : 90 Starting : Thread10 fromId : 91 toId : 100 Thread8 processing : 71 : user_71 Thread2 processing : 11 : user_11 Thread3 processing : 21 : user_21 Thread10 processing : 91 : user_91 Thread4 processing : 31 : user_31 Thread6 processing : 51 : user_51 Thread5 processing : 41 : user_41 Thread1 processing : 1 : user_1 Thread9 processing : 81 : user_81 Thread7 processing : 61 : user_61 Thread2 processing : 12 : user_12 Thread7 processing : 62 : user_62 Thread6 processing : 52 : user_52 Thread1 processing : 2 : user_2 Thread9 processing : 82 : user_82 ......
After the process is completed, 10 CSV files will be created.
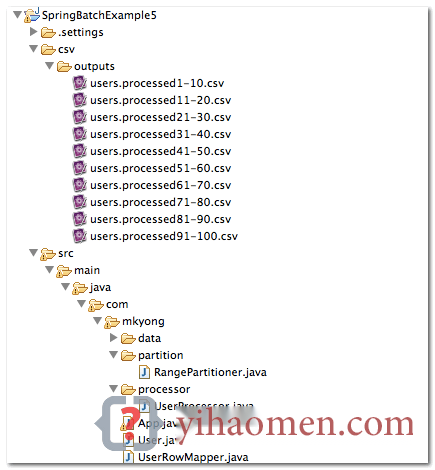
users.processed1-10.csv
1,user_1,pass_1,20 2,user_2,pass_2,40 3,user_3,pass_3,70 4,user_4,pass_4,5 5,user_5,pass_5,52 6,user_6,pass_6,69 7,user_7,pass_7,48 8,user_8,pass_8,34 9,user_9,pass_9,62 10,user_10,pass_10,21
6. Misc
6.1 Alternatively, you can inject the #{stepExecutionContext[name]} via annotation.
UserProcessor.java - Annotation version
package com.mkyong.processor;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import com.mkyong.User;
@Component("itemProcessor")
@Scope(value = "step")
public class UserProcessor implements ItemProcessor<User, User> {
@Value("#{stepExecutionContext[name]}")
private String threadName;
@Override
public User process(User item) throws Exception {
System.out.println(threadName + " processing : "
+ item.getId() + " : " + item.getUsername());
return item;Remember, enable the Spring component auto scanning.
<context:component-scan base-package="com.mkyong" />
6.2 Database partitioner reader - MongoDB example.
job-partitioner.xml
<bean id="mongoItemReader" class="org.springframework.batch.item.data.MongoItemReader"
scope="step">
<property name="template" ref="mongoTemplate" />
<property name="targetType" value="com.mkyong.User" />
<property name="query"
value="{
'id':{$gt:#{stepExecutionContext[fromId]}, $lte:#{stepExecutionContext[toId]}
} }"
/>
<property name="sort">
<util:map id="sort">
<entry key="id" value="" />
</util:map>
</property>
</bean>Done.
References
From:一号门
COMMENTS